

Een belangrijk onderdeel van je website is een klein tekstbestandje genaamd: robots.txt. Het doel van dit bestand is het geven van instructies aan ‘robots’ die het web crawlen. Deze bots houden zich aan de zogenaamde Robots Exclusion Standard.
De werking van de file is vrij simpel. Een bot (of robot) brengt een bezoek aan je website. Laten we zeggen: https://www.stramark.nl. Voordat het begint met crawlen van de website controleert de bot eerst het robots.txt bestand:
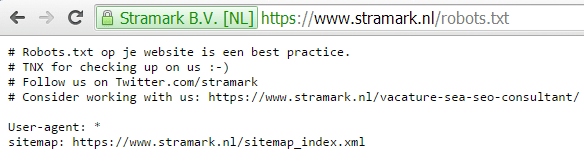
Een ” # ” zorgt er voor dat een bot de tekst op die regel niet kan lezen. De eerste regel die voor een bot leesbaar is dus:
User-agent: *
Dit stukje code geeft aan dat elk type bot toegang krijgt tot de website. De bot kan dus beginnen met crawlen.
De tweede regel die de bot tegen komt is:
sitemap: https://www.stramark.nl/sitemap_index.xml
Dit is een verwijzing naar de sitemap van de website. Verwijzen naar je sitemap in het robots.txt bestand wordt gezien als een best practice.
Je zou de sitemap van een website kunnen vergelijken met een wegenkaart van een land. Een robot kan nu vanuit het robots.txt bestand gelijk de “wegenkaart” van de website vinden en daarmee heel efficiënt jouw website crawlen.
Daarbij is het wél van belang dat je website een sitemap heeft die zichzelf op regelmatige basis update. Als een robot via de sitemap bepaalde pagina’s niet kan vinden, omdat ze zijn verwijderd of omdat ze van naam zijn veranderd, dan krijg je een foutmelding in Google Webmaster Tools. Dit wil je voorkomen.
Disallow:
Een tweede opdracht die je een bot kan geven is het niet bezoeken van je website of bepaalde delen er van. Dit doe je door Disallow: toe te voegen. Hiermee weiger je een bot bepaalde delen van je website te crawlen met als resultaat dat ze niet in de zoekresultaten terecht komen.
Door de onderstaande code toe te voegen vertel je een bot om je website niet te crawlen. Dit doe je bijvoorbeeld als je website nog in ontwikkeling is.
User-agent: *
Disallow: /
Als je niet wil dat een bot je login pagina crawlt dan ziet dat er als volgt uit:
User-agent: *
Disallow: /login/
Je kan er verder nog voor kiezen om een bepaalde pagina’s in je website niet op te laten nemen in de zoekresultaten van een zoekmachine. Een voorbeeld hier van is je afrekenpagina.
User-agent: *
Disallow: /checkout/
De kanttekening die bij Disallow: geplaatst moet worden is dat het tegenwoordig steeds minder wordt gebruikt. Het afschermen van bepaalde delen van een site kan er voor zorgen dat css, javascript of andere vitale onderdelen van je site worden geblokkeerd bij het laden. Dit kan van invloed zijn op de functionaliteit van je website.
Allow:
Verder heb je de mogelijkheid om aan te geven dat bepaalde sub-mappen of files wel gecrawld mogen worden. Dit doe je door Allow: toe te voegen aan de robots.txt. Hiermee vertel je een bot dat het toegang krijgt tot een specifieke map of file. Een voorbeeld:
User-agent: *
Allow: /map-x/plaatje.jpg
Disallow: /map-x/
User-agent: *
Allow: /map-x/map-y/
Disallow: /map-x/
Belangrijke overwegingen
Er zijn twee belangrijke onderdelen die je altijd in overweging moet nemen.
- Het robots.txt bestand is een vrij toegankelijk bestand. Het is om deze reden niet aan te raden om wachtwoorden of andere belangrijke informatie op te slaan in het robots.txt bestand. Nog is het aan te raden om te refereren aan pagina’s waar vertrouwelijke informatie staat.
- Bots kunnen zo geprogrammeerd zijn dat ze het robots.txt bestand negeren. Malware en ander virus-achtige software zal je website dus alsnog crawlen.
Waar moet je het robots.txt bestand staan?
Het robots.txt bestand dient in de root van je domein te staan. Je kan dit controleren door achter je domeinnaam robots.txt in de typen:
- https://www.stramark.nl/robots.txt
Verder dient het bestand aangeduid te worden met kleine letters:
- Fout: https://www.stramark.nl/Robots.TXT
- Goed: https://www.stramark.nl/robots.txt
Overzicht functies Robots.txt
| User-agent: * | Geeft aan dat alle robots de website mogen crawlen. |
| Disallow: | Geeft aan dat bepaalde gedeeltes van je website niet door robots mogen worden gescand. |
| Allow: | Geeft de mogelijkheid om specifieke mappen en files wel te laten crawlen. |
| sitemap: | Geeft aan waar de locatie van de sitemap van je website staat. |
| # | Geeft je de mogelijkheid tekst toe te voegen aan je robots.txt bestand. |
Tot slot: Dit is wat Matt Cutts over de Robots.txt te zeggen heeft:

Reacties